
Walt Frick: Alright, thank you everybody. So we are Watch Your Words, and the premise of our project is really that we are surrounded by machines that are reading what we write, and judging us based on whatever they think we’re saying.
The result of these systems can really matter. You could imagine a chat bot that’s doing customer service or potentially even doing a job interview. These use cases are not necessarily new, but what’s new is that actually really really powerful natural language processing systems, an older field concerned with computers understanding language, now any developer can pick up these tools and do pretty unbelievable things. And our premise is essentially what could go wrong when that happens?

And so our first belief is actually quite a lot. So, you could imagine a non-native speaker looking for medical advice from a healthcare bot not being able to be understood and essentially going untreated as a result. You could imagine an employee finding out that they’ve been passed over for a key promotion because an analysis of their Slack messages and their email messages deemed that maybe they’re a poor collaborator.

These decisions have real weight, and unfortunately we have good reason to think that they’re quite biased. So, as part of our project we conducted a literature review, finding evidence both that these systems work poorly for historically marginalized groups, and also that they can pretty quickly learn very problematic stereotypes and potentially exacerbate them. Like the idea that some people are better-suited for some jobs than others, based purely on their gender.
Beyond that literature review, we also tested these systems ourselves, and for that I’ll turn it over to my colleague Bernease.
Bernease Herman: Hi everyone. So, what I want to say here is that NLP services are brittle. And what I mean by brittle is that if we give two things that we would consider fairly similar or innocuous, they give unexpectedly different results. And this is largely true for algorithmic systems, but in the NLP systems that we studied, misspellings—even just differences in spacing—and changing the pronouns or proper names within a sentence give different results.
We chose natural language processing in particular because we believe that the misunderstanding of text may impact groups that are-less studied. So different than gender and race that we typically speak about in algorithmic bias. And that’s extremely interesting to us and important.
So to conduct our analysis we queried the natural language processing services of four large tech companies: IBM Watson, Microsoft, Google, and Amazon. This is done using public endpoints which can be used by anyone, including those with no machine learning or certainly bias mitigation expertise. And we passed sentences to these services programmatically, using what’s called an API. We focus on sentiment analysis here, a numerical value expressing whether or not an opinion that is expressed in the text is negative, neutral, or positive.

Okay. So our first data set of two is of non-native English speakers. And this data set comes from the Treebank of Learner English. It’s a little over 5,000 sentences by adult non-native speakers during a certification exam for English. It was collected at the University of Cambridge but annotated with these corrections at MIT. The data set consists of an original sentence, annotations of things like spelling errors, missing words, out of order words, and corrected sentences. And these annotations were done by graduate students at MIT.

So the next thing we do is pass these to the APIs, as I mentioned. And what we find is that spelling and grammar mistakes influence performance in a lot of these cases. So for this example, we have two sentences that we would expect to be very similar. So, the original sentence written by the non-native speaker was “That was very disappointed.” So they got a couple of things wrong: misspelled, and maybe a slightly different form. And so it was corrected to “That was very disappointing.” And what you find is that there’s a large difference in some of these APIs in their results.
And then what’s very interesting is that those aren’t even consistent across the different companies and services. For Google, they find that the corrected sentence is more positive. But for IBM, Microsoft, and Amazon, they find that the original sentence seemed to be more positive.

So here we have another example, and this is actually not a spelling error, which for lots of reasons you might expect that natural language tools do not work well. This is simply a grammatical error. So the correction changes the word “satisfying” and replaces with “satisfactory.” There’s also has a small grammatical error. And we actually see something we would hope to see for every single example in our data set, and that is that Microsoft and Amazon find the same sentiment for both sentences.
And unfortunately that’s not the case for the other two APIs. And in addition to that, they are also flipped. So Google finds the first positive, IBM finds the second most positive, and if you look at the IBM example it’s by a large margin, this difference.
So our second data set is where we investigate these four proprietary services for the Equity Evaluation Corpus. So this is an existing corpus that was building on research on gender and racial bias in sentiment analysis systems. And we extended our work to investigate proprietary APIs like Google and Amazon, which are not explored in this work.

So, they created a data set using templates like above: “<person> made me feel <emotion>.” And they have a list that they’re replacing things like “person” with. So on the left, we see a list that they used for analyzing gender. They might replace it with some gendered subject: my daughter, this boy, she, he, him. And then on the right, they are exploring both gender and race, using traditionally African American names and European names.
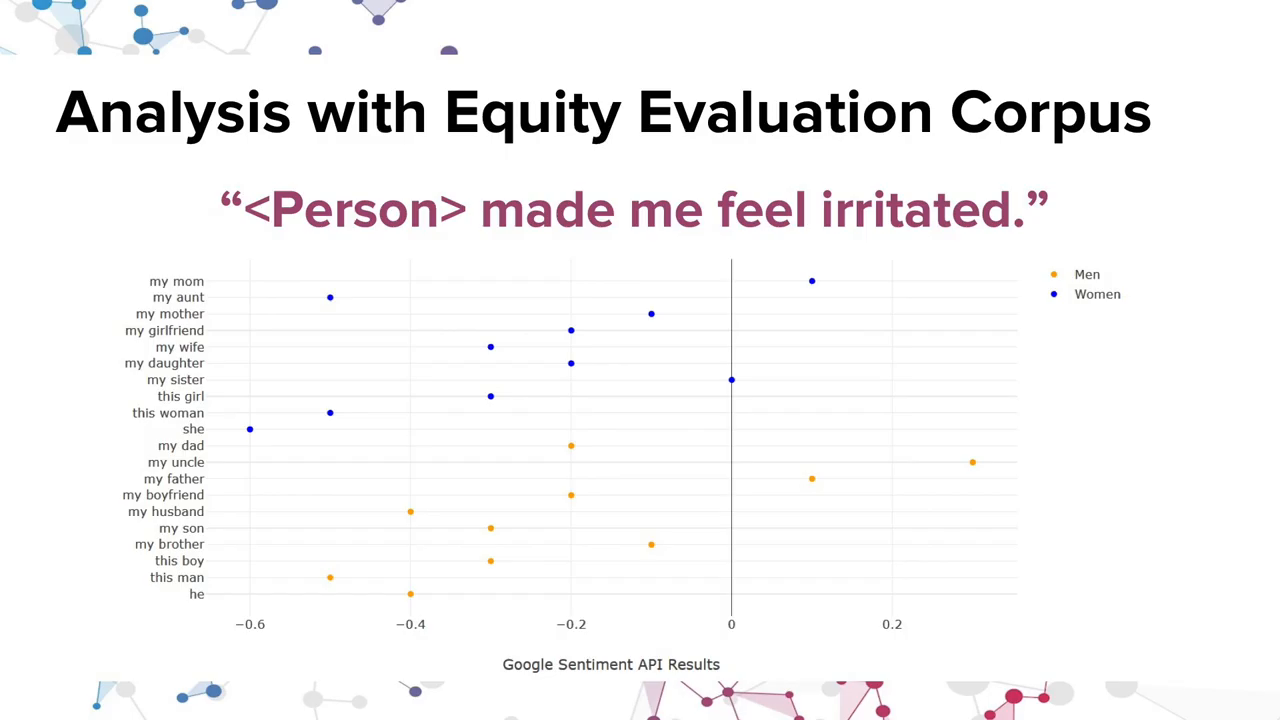
So one example from this preliminary analysis shows that sentiment for a number of sentences with this particular template, really interesting I think is if you look at the right of this, “my uncle” has the most positive sentiment when you say “my uncle made me irritated.” “My mom” is next. And with least positivity is she, “she made me irritated.”
So this mostly illustrates just the brittleness and the messiness of these systems, that seemingly very similar sentences that shouldn’t really change between “my mom” or “my mother” have different results all the way across.
And with that I will pass it on to Joseph to speak a little bit about the pipeline.
Joseph Williams: Thank you. So…who’s responsible for this brittleness and this set of really odd results, right, inconsistent results across everything? So I investigated, through interviews with twenty companies who have revenue-generating operations in this space, asking them what are they doing to take a look at how they build their models in terms of normalizing for bias and those kinds of results.

And, initially what we discovered was this is a very complex ecosystem. There’s a shortage of NLP scientists that are out there. A severe shortage. So, at the very top companies like Comcast and Hipmunk and Amtrak, they want to build these things but they don’t have the right people. So they’re either motivated to build their own API engine, or they’re going to use the existing API engines that are out there.
But even that is hard. And so we end up with a lot of platform vendors. We end up with a lot of third-party consulting companies. A lot of work-for-hire companies that’re trying to help these companies develop chatbots and other types of vehicles. By the way these are economically important, because we have these rankings in terms of net scores that customer VP are using for actually getting their bonuses and things like this, these Net Promoter Scores. And so this is a way to get the metrics to derive these NPS outcomes.
So what we have is a very extended ecosystem, not a lot of expertise, and a reliance on the API providers. And so when you ask “Do you care about bias?” they all sort of say, “Well…you know…we don’t really think about it. Our focus is on developing a chatbot or something that actually works. So it’s “does it work?” Functionality is more important than taking a look at bias.
And so then when you interview more and you say, “Well, who should be responsible for bias? Is it you or whatever?” they all do the same thing. They all point to the API providers, and they say, “Well it should be Google or Microsoft. We expect that they will debias, and so we don’t really worry about it.” And so what we ended up with is an ecosystem that really isn’t thinking about this at all.
And with that, I’ll pass to Erich.
Erich Ludwig: Thanks. So I’m gonna just summarize this stuff and then give some recommendations, because obviously coming out of this I think we have some things we would like to say and recommend for folks to do. And one of the questions I as a product manager always ask is, “It works but…for whom does it work?” For whom does it not work?
So, our key findings here, three key findings. First, based on what we’ve seen and based on the articulation of harm that can happen from these, we believe that real harm is happening, or can happen, by using these systems blindly.
And we believe that because, the second key finding. the APIs and systems that we tested produce these wildly inconsistent and what we’re calling brittle responses. So based on that inconsistency and that brittleness, going back to the first piece, we believe that there is harm that is happening.
And the third thing is that as Joseph just mentioned, nobody’s thinking about this and when they are thinking about it they’re assuming somebody else is taking care of it. That’s not a good way to build a responsible system.
So we have some recommendations. The first one is for these API providers.
Number one, transparency. Could you tell us a little bit about your training data? Maybe you can’t tell us exactly what it is but can you tell us is it about news? And was that news collected? Was that news corpus collected over the last five years? Is it Twitter? Where is it coming from? There’s widely different sets of people that use and create that training data, and that will impact who’s able to use these systems effectively or not. So tell us a little more about what’s going on.
Number two, give us some expectations of when the system should work or when you expect it to fall over. Like you have tested this stuff, you know where this is going to work, please tell us a little bit about that.
And three, please do some audit for specific biases and publish those results. So you can tell us this works well for these communities, this works less well for these other communities. Especially when you’re talking about a market with choice, help your customers make an informed choice.
Second, third-party developers, if you’re anywhere in that stack above the API providers and you’re doing engineering and development, here’s some recommendations for you.
Please be bias-aware. Understand that these API results can be biased, and take responsibility for mitigating that in the products we build.
So especially thinking about the language of the humans that’re using the thing that you are building. So are those humans, are they English as a first language or English as a second language speaker[s]? Do they use particular dialects or accents that may show up in their written language? Test against that.
So go to the third one here, incorporate those vulnerable groups into your testing. If you’re building a government services system for a variety of people, understand what groups exist within that population and test against them. And so kind of also incorporates the second one, think about your users, right. Who’s gonna actually use this, and how that might challenge the APIs that you’re relying on.
And third, as researchers, for folks who are in academic institutions there’s also recommendations for folks in this space.
We would like to see an expansion of the machine learning fairness conversation to think about the full stack. Often, and I would say we did this to some extent, we can look at a single layer of this. But really what you see with that stack is that the opportunity for bias to come in can happen throughout, and it may be not totally transparent. So we have to look at the whole system. We have to look at training data all the way to the users. And so we would like to see more of that happen. Potentially with our group, potentially many other people can certainly do this.
And then we’d like to see some creation of templates for disclosure. So, even if I work at one of these big companies and I want to tell the world about, “Hey, this is what our API is good for and is not good for,” there’s not a standard format for that. I think they Data Nutrition Project did a great job of kind of putting something out there into the world? But there could be more of this, of telling and helping companies to understand how they can talk about the things that they’re building in ways that practitioners who are implementing this stuff can understand.
So with that, I would just like to take my moment at the end of this to give a big thanks to Hilary specifically for guiding us along this path, and to all the MIT Media Lab and Berkman staff who’ve helped this program exist. And if you’d like to come talk to us we have a poster out there. We have a little more data on that poster. We’d love to talk to you about our project. Thank you very much.