
Thank you very much for having me. I really appreciate the opportunity to come and talk.
As Alice pointed out, I’m a journalist and filmmaker. I just wanted to give a little bit of background on my own interest in this subject. I don’t come from a coding background. My interest in technology really comes from my interest in popular culture and my belief that if you want to understand popular culture, you really need to engage with technology and the questions that it poses in the world, which are really key for understanding not just how the world works, but really our relationship with the world, our relationships with each other, and our selves and issues of identity.
You look at any period in history, and imagery and metaphors are often drawn from popular science, and today there’s no science more popular than computer science. We can see this from the pervasiveness of tools like Facebook, Google, and Twitter. And when you think about it, the algorithm is the key metaphor of the age. It interested me because of the idea of just how much of our lives can be algorithmized, or sort of routinized and automated. That’s what I would like to talk about today.
One of the most famous statements made about the entertainment industry was made by the screenwriter William Goldman. Back in the 1980s, Goldman, who wrote Butch Cassidy and the Sundance Kid, and All the President’s Men, and various films like that, was working on his autobiography, Adventures in the Screen Trade. One of the things that his editor was very keen for him to do was to look back on his time working in the Hollywood trenches and try and draw out a lesson that he would be able to pass on to film fans, or really anyone who wanted to follow in his footsteps.
He did, but the only lesson that he could come up with was the idea that when it comes to the entertainment industry, nobody knows anything. He wasn’t saying this necessarily to insult the people who had rejected scripts and things over the years, but rather the idea that until a film arrives on the cinema screen, nobody’s able to predict whether it’s going to become a hit or a flop.
As a filmmaker myself, I’ve always been really interested in this idea of whether or not we can predict hits. You speak to anyone who works in the entertainment industry, and everyone has their was stories of that film they were sure was going to become a hit which somehow became a miss. There are niche films which appeal to everyone, and perhaps more likely, films that are designed to appeal to everyone which somehow appeal to no one. Nobody has an unblemished record. When you consider the fact, it’s kind of difficult to blame them.
Back in the mid-2000s, there were two films which were doing the rounds in Hollywood, and I’d just like to talk you through them.

This is the first one. It was called Project 880. Project 880 was a science fiction film. It was directed by a very successful Hollywood filmmaker who’d had a string of hit films previously. In fact, the last film that he had made prior to Project 880 had become the first film in history to gross a billion dollars at the box office, and had racked up eleven Academy Awards at the Oscars. However, he hadn’t really done very much for the decade prior to making Project 880. He was also asking for quite a lot of money to make it, $237 million. The film he was proposing to make didn’t have any major stars in it, and it was shot in the then-experimental 3D format. Nonetheless, he was given the money to make the film, and when it arrived in the cinema it was labeled, in the words of an early reviewer, the most expensive American film ever made and possibly the most anti-American as well.

Let’s jump to another. Project X was doing the rounds pretty much at the same time as Project 880. Like Project 880, it was also a science fiction film, again from a very successful director who had previously directed Wall‑E, Finding Nemo, and had worked on all of the entries in the hugely-successful Toy Story series. It was based on a classic children’s story, and the script was co-written by a Pulitzer Prize-winning author. He was asking for quite a lot of money as well, a shade more than the director of Project 880. He was asking for $250 million. And again, he was also shooting in the experimental 3D format. He was also given the opportunity to direct the film.
What is interesting to me about this is that on paper, both of these seem like they should be hits. In fact, they sound like they should be fairly similar hits. Both from successful directors, both mainstream Hollywood films, both science fiction movies, both 3D, etc.
However, they came to slightly different fates. Project 880, as I’m sure a number of you if you’re film fans will have guessed, turned out to be James Cameron’s Avatar, which became the first film in history to earn $2 billion at the box office, so a pretty good return on investment for the people who had bankrolled it.
Project X on the other hand, didn’t become the next Avatar, but rather became the first John Carter, a film which was critically panned and lost $200 million in the box office, and actually resulted in the firing of the head of the studio that had made it, despite the fact that he had taken the job after the film was already in production.
As per William Goldman, nobody knows anything.
I was fascinated [by] this idea, and I started looking around for other examples of trying to predict hits and misses (presumably trying to predict hits) across the entertainment field. I found a great quote from Somerset Maugham which wasn’t about movie making, but was actually about novel writing. He said there are three rules for writing a successful novel, unfortunately nobody knows what they are. This got me wondering, does nobody know what they are because Maugham was being facetious and they don’t exist as rules, or does nobody know what they are because as humans we’re not good enough at pattern recognition in order to be able to find the high-level patterns which dictate what’s going to become a hit?
Fortunately, this is an area that computer science can help with. Here in London there’s a fascinating company called Epagogix which works with some really big movie studios in Hollywood and predicts how much films are going to make at the box office. It does this using a neural network. For those of you who don’t know what a neural network is, it’s a sort of vast artificial brain for exploring the relationship between cause and effect, or input and output, in situations where that situation is complex, or unclear, or possibly unknown.
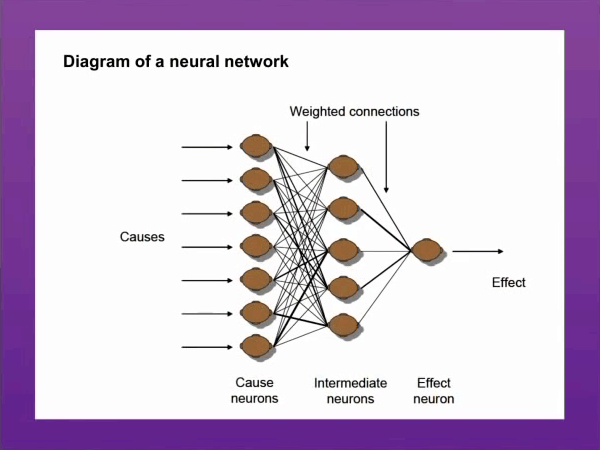
Essentially, they’re given scripts by the movie studio they work with, and they also take scripts for films that they’re not working on just as a way of growing their database, and they divide it into millions of different components, in fact 30,073,680. Thirty million unique scoring combinations, which are far more than you or I would ever be able to come up with if we were asked to write down the components of a successful film. We might come up with ten or fifteen at best, and struggle a little bit after that.
Epagogix, however, has been very successful for the studio that it works with. And interestingly, it doesn’t just churn out a particular number and that’s the end of it. It can also make creative decisions because it can look at parts of the script where the yield is perhaps not where it could be, and suggest that you tighten up this moment in the fifteenth second of the fourteenth minute of the film, and we predict that this will have a knock-on effect which will result in you earning X amount more at the box office. Epagogix is really a vision of a future in which machine logic can be embedded in the creative process.
So let’s jump to a different field, one that from my perspective as an outsider seemed like it should be more straightforward to automate. Not because it’s a less complex subject but just because it’s one that’s more logical and more rule-based. In some ways, academic publishing would fall into this kind of category. But the area is law.
It stands to reason that these areas should be more predictable, and it should be possible to come up with consistent rules that we would be able to use to predict outcomes and offer automated solutions to our everyday logical problems. It turns out, however, (and this is perhaps something that you know from your own work within academic publishing) that something that seems like it should be fairly straightforward to automate doesn’t always turn out to be the case. In fact there was a fascinating study which was done last year which shows just how difficult it is to turn even the simplest of law into an algorithm.
The law in question was an algorithm designed to determine whether drivers had broken the speed limit, and then to give them a ticket if it deemed that they had. As far as laws go, this seems like it should be a fairly straightforward one to automate. It’s a fairly binary law. You either drive above a certain limit and get a ticket, or you drive under the limit and you don’t get a speeding ticket. However this showed how difficult it is to automate even that.

For the experiment, fifty-two computer programmers were brought together, and they were all given two data sets. One data set showed the legal speed limit along a particular route and the other data set showed the speed of a vehicle, which was a Toyota Prius, along that route, taken from an on-board computer. Comparing the two data sets you should therefore be able to determine when the car had exceeded the speed limit. I should also say that this journey was a pretty typical commute to work; it was about a half-hour journey in total, and it was fairly uneventful. It was completed safely and without any incident.
When the fifty-two computer programmers were brought together, they were split into two groups, and they were each asked to do something slightly different. One group was asked to create an algorithm which would conform to the intent of the law, and the other group was asked to write an algorithm which would conform to the letter of the law. On the surface, both of these seem like they should be achieving the same end, but in fact they achieved vastly different results.
The “intent of the law” group issued the amount of tickets that we would expect for something like this, between 0 and 1.5. We would likely be slightly irritated if we got a ticket for driving to work, but at least it’s within what we would expect to happen. The “letter of the law” group, however, issued a slightly more draconian 498.3 tickets.
This astonishing disparity illustrates that the scenario where deciding legal cases by algorithm might not perhaps be quite as close as we assume that it is. But it is, however, something that we’re going to have to grapple with going forwards. Just this week, in fact, we saw Google rolling out the first mass-market (at least in name) prototype for its self-driving car. And we’ve also read a lot about ambient law, which is the idea that laws can be embedded within the devices and environments around us. So we might have a car which is able to determine whether its driver is over the legal alcohol limit and then decide not to start as a results. Or we could have the Smart Office which regulates temperature, and if a certain limit is reached or exceeded, decides to sound an alarm or turn off computers or something similar to that.
But this shows why this is going to be such a challenging thing to achieve. Laws aren’t based on hard and fast rules, as it turns out but rather a sort of high level of what we could call intersubjective agreement. And implemented incorrectly or without understanding not necessarily the code at the heart of it but the humanity at the heart of these laws can result in highly problematic situations.
Perhaps the single most revealing statistic from the speed limit experiment happened afterwards when the group was reassembled and were discussing what they had learned. What was particularly fascinating was when they were asked whether they would be happy to drive on the road under the conditions that they had just been responsible for coding. Here the “letter of the law” group, who had issued the draconian number that I mentioned earlier, 94% claimed that they wouldn’t be happy to drive on the road under those conditions. In fact, only one said that they would, and said that they would do so only on the proviso that they had a backdoor which would enable them to somehow circumvent the laws that they had coded, which probably wouldn’t be happening.
So let’s jump now to one last area. This is from man-made laws to natural laws. What about behavior, and particularly what about love? The idea that we might be able to program our own boyfriend or girlfriend isn’t a new one in terms of science fiction. I’m sure lots of you also grew up in the 80s and remember such films as Weird Science. More recently we’ve had a millennial take on that in Spike Jonze’s film Her which also deals with the idea of AI and whether or not we could fall in love with an AI and what the implications of that would be. In fact, there have been some high level AI proponents or AI experts who have investigated this area and have come to some interesting and potentially worrying conclusions about, as algorithms get better and robotics get better, not only do they predict that an algorithmic lover might become possible, but also that in some ways it might become preferable because we would be able to fine-tune our other half.
This is, for the most part, either Hollywood science fiction or the kind of stuff that’s tacked onto the end of PhD thesis as a sort of hypothetical ethical issue that we will be dealing with at some point down the line. However, I met a pretty interesting programmer while I was writing my book, a guy called Sergio Parada who lives in California. Sergio Parada started out his carreer working as a video game designer working on the Leisure Suit Larry series of games.
For those of you lucky enough not to know what the Leisure Suit Larry series of video games are, it was essentially a 1990s series of bawdy adult video games in which you play a sort of affable loser as he progresses through a scenario of bedding an increasing number of partners. It was while Parada was working on the last entry in the game, which was in fact never released, called Larry Explores Uranus, that he came up with the idea of creating not a girl simulator, but a relationship simulator. He called it Kari, standing for the Knowledge-Acquiring Response Intelligence.
One of the interesting things about Kari, she’s a chatterbot, which is an algorithm designed to simulate an intelligent human conversation, which is of course an idea which goes back to Turing. The interesting thing about Kari, especially given Parada’s previous work, is that unlike a regular video game, in Kari there was no set narrative. It wasn’t like you would reach the end of a level and that would be it. The reward for the player was a relationship, as with any successful relationship, which grows and develops and deepens over time. Of course to ensure that this happened, Parada ensured that you would be able to modify Kari in a way that you may not be able to modify your significant other in the real world.
This was done by way of a series of sliders, the most romantic way to do this, obviously.
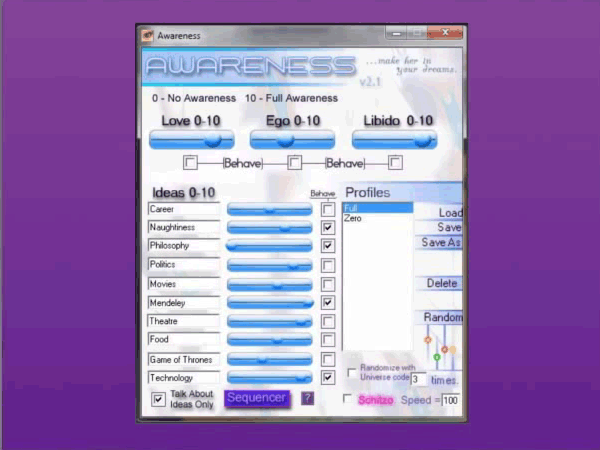
This means that Kari can live up to the kind of the prostitute’s classic sales pitch that I can be whoever you want me to be. You can literally fine-tune Kari to be your ideal partner and you can, for example if you notice that she was being a bit too aloof you might lower her independence level. Or if you notice that she jumps too quickly from topic to topic, you might raise the amount of seconds between unprovoked comments.
For me the most interesting aspect of Kari isn’t just that it challenges our idea of what represents a relationship but that in a way it makes us aware of the degree to which our relationships with one another are essentially high-level social algorithms which are acted out according to a step by step framework.
So if something like love can be automated, then what next? The question is sort of whether everything can be subject to algorithmization, and I think all of you are probably in a better position than I am to answer this question. The answer currently is “no.” There are certain things that currently can’t be carried out by algorithm. For example, image recognition frequently requires far more training examples than a child in order to be able to recognize particular objects. Or marking essays in a subjective area like the humanities could also be challenging to automate.

But things are improving, or at least they’re changing very very rapidly. We have a number of fields which previously wouldn’t seemed impossible to automate which today, there are very successful companies working on automatic or algorithmizing. For example, you have a field like my chosen profession of journalism. There’s a company in America which is very successful called Narrative Science which is working on creating algorithms which can compile news stories. Currently this is only used for compiling financial reports or low-league sports match write-ups. But long-term it could perhaps do more, and I know the CEO of Narrative Science has claimed that within the next ten to fifteen years, he believes it’s going to win the Pulitzer prize for investigative journalism. Maybe a sort of PR spin or wishful thinking on his part, but I think it raises some interesting questions.
Another area is music composition. In 2012, the London Symphony Orchestra took to the stage to perform the works of Iamus, which is a music composing algorithm which has composed more than a billion compositions across a wide range of genres.
But some of our concern around this is about employment. Ten, or maybe fifteen, years ago it would’ve seemed ridiculous that a long-distance driver could have his or her job replaced by an algorithm. Today of course, as we mentioned earlier, there’s the Google self-driving car. This is clearly an area which is, if not being directly threatened within the next few years, at least there’s the potential for that to happen.
But there’s also a bigger, deeper question about whether there are parts of life that are simply too precious to automate, or too integral to our conceptualization of what it is that makes us human. To go back to the first example, if an algorithm can make creative decisions, as with Epagogix, what does that say about art and creativity, and about our own humanity? In the case of art, and algorithm doesn’t have knowledge about its own mortality and the sense of urgency that comes with it. It might be able to achieve pleasing sounds, or string together pleasing images, but are these ever going to match the emotional complexity or the creative innovation of a painter or writer or filmmaker. Ultimately, writing this book left me with far more questions than it did answers, and hopefully I will probably not be able to give you definitive answer, but I can at least give an effort to do so if you have any questions.
Thank you very much.
Further Reference
The early review of Avatar mentioned near the beginning.
There was also a Q&A session after Luke’s presentation.