
Elizabeth Dubois: So, I am Elizabeth. I’m going to talk to you today about positionality-aware machine learning. We are going to start off with a question. Tomato: fruit or vegetable, what do you guys think? [various answers shouted from audience] Fruit, vegetable, right.
Okay. It’s a matter of perspective. It’s also a matter of context in which you want to use that answer. If you’re a botanist, you say fruit. If you are a nutritionist, you say vegetable. Lawyers and judges in the US have agreed: vegetable. Computer vision researchers? say it’s miscellaneous.
This idea of classification, it’s the process of assigning a name or a category to a particular, idea, concept, thing. It’s a process that we go through in our daily lives continually. The idea of classification is also the idea of creating taxonomies for understanding the world around us and reducing the large amounts of nuance and detail that there are in the world usefully. We see it when we’re trying to understand how diseases spread around the world. We use it when we’re trying to understand what online harassment looks like. We use it to understand differences in race or gender.
Gender’s a particularly interesting one, particularly in the kind of Western societal context where at one point we saw gender as pretty much agreed upon as a binary variable. There were two options. But now that’s no longer the case. So if we’re thinking about these classification processes and trying to embed them into the machines we’re building, we need to be thinking about it critically and in the context that we’re currently in and what might change moving forward.
We do not always design models that affect people’s lives or have potential harms. […] Like, our auto-toner model for image re-colorization, that does not inflict harm.
Or, maybe it does?
It is kind of a weird algorithm that may lead to white washing … actually you know, … I take it back.
Extract from user interviews, Senior Data Scientist, Major US News Publication [slide]
This is a quote that we had from one of the many user interviews we conducted with different ML and AI engineers. This woman is at a major US news organization, and she talked about the idea of classification and when it might present problems in terms of harms it could cause. She said there are sometimes when it just doesn’t matter. It’s not an issue to do with harm. She started with the idea of okay, “our auto-toner model for imagery colorization, well that’s not going to cause anyone harm.” Paused. Thought about it. Actually maybe it does. It’s kind of a weird algorithm that may to whitewashing.
And so this is something we saw time and time again as we were asking these practitioners to think about their classification choices and when they might be problematic, that once we started digging into that problem they realized there was this potential for problematic decisionmaking that on the surface wasn’t an issue in the first place.
And so this is where we come to our idea of positionality. Positionality is the specific position or perspective that an individual takes given their past experiences, their knowledge; their worldview is shaped by positionality. It’s a unique but partial view of the world. And when we’re designing machines we’re embedding positionality into those machines with all of the choices we’re making about what counts and what doesn’t count.
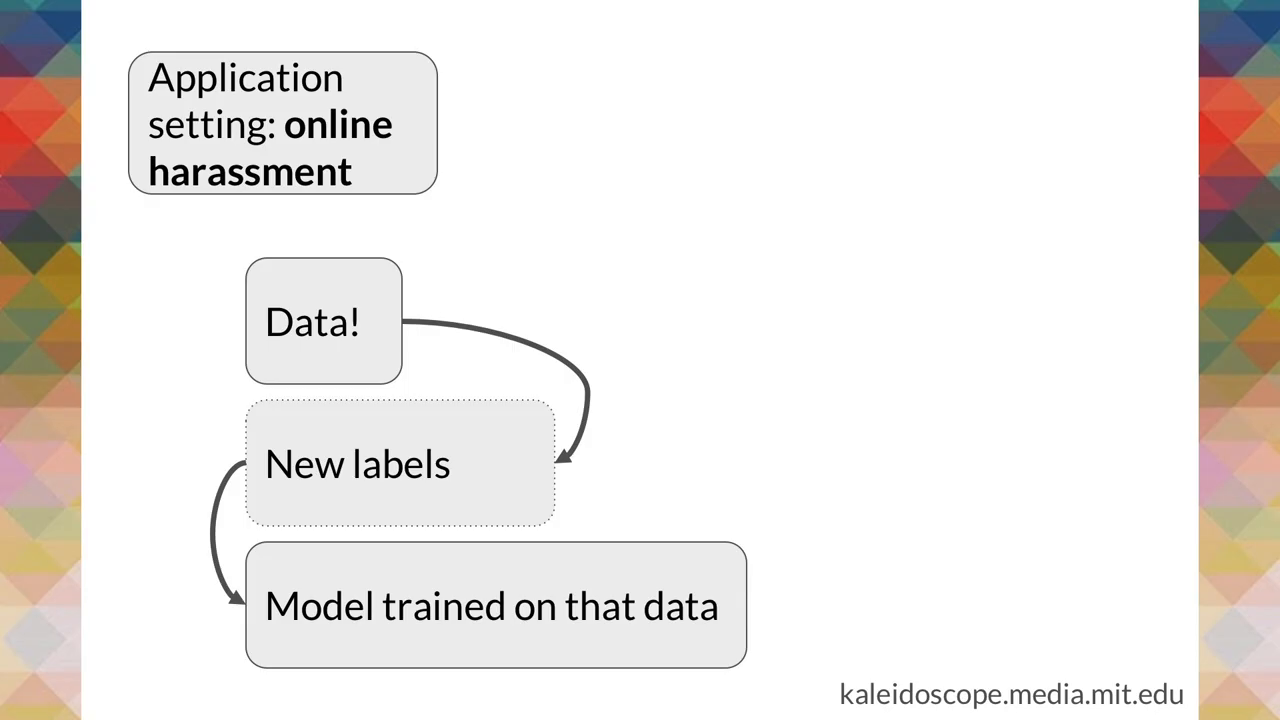
So this is a very very simplified data pipeline, okay. This is when we go from data into our ML model that we are trying to train. I’m going to use the context of online harassment. Let’s imagine we have a whole bunch of tweets and we want to just find whether or not those tweets are exemplifying harassment or not.
Well, we would grab our data. We would apply new labels to that data: harassment/not harassment. And then we’d train a model on it so it could predict.
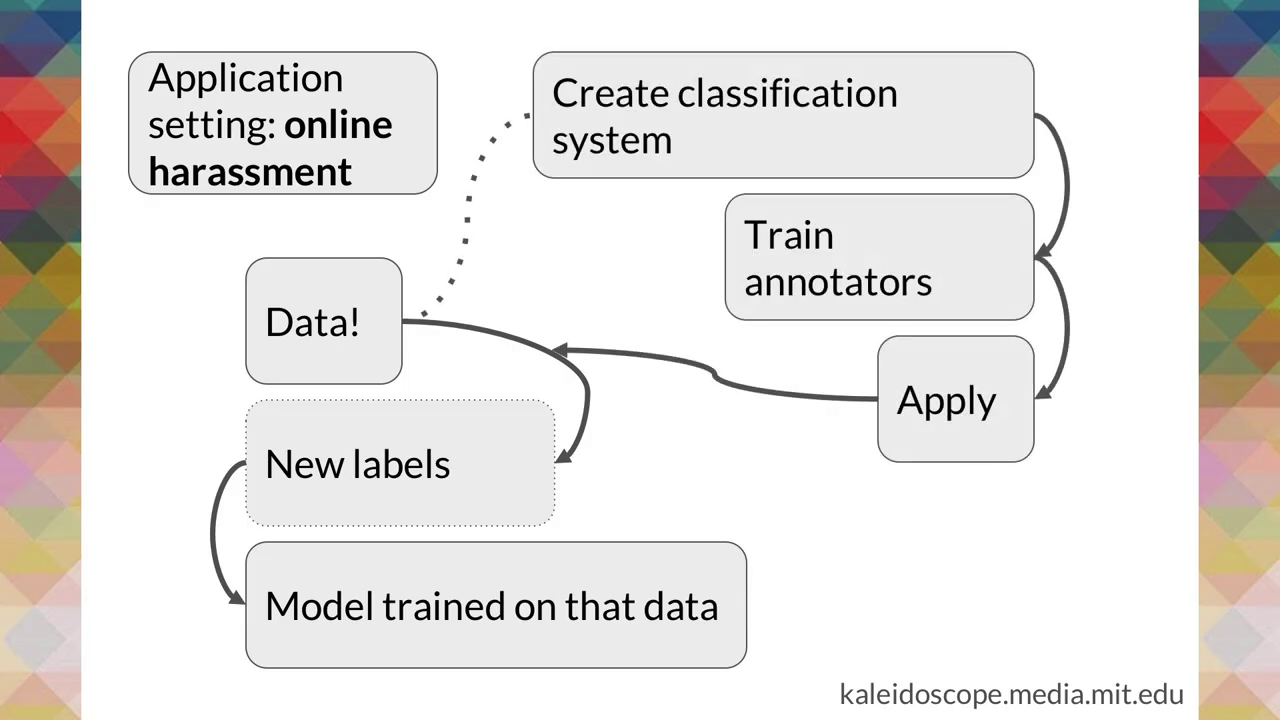
This requires a really complex classification system, right? So we have a system to decide what counts as harassment or what doesn’t. We have to train a whole bunch of annotators to literally go through the data piece by piece and assign those labels. Then they apply that. And that’s when we get to feed into that model.
So thinking about online harassment, in a project I worked on we started with three categories. That was our classification system, our taxonomy. We had positive, neutral, and negative. Every tweet was going to fit into one of these categories.
Our annotators could not agree. Three categories did not work. And it was because there was a bunch of boundary cases between neutral and negative. It caused tons of problem, we could not get good inter-coder reliability or inter-rater reliability, which is a common tool to use to assess agreement.
We added a fourth category called “critical,” and all of a sudden our annotators agreed the majority of the time. We had to redesign our classification system in order to respond to the actual data the way that it was being presented and the way humans interact with that and understand it.
So what we’re saying is, to interrogate these classification systems we need to be thinking about what counts, in what context. We need to be thinking about who those annotators are, why we’ve selected them, how they’ve been trained, at what moment in time. And we need to think about the actual application of the classification systems, and question whether or not there is sufficient agreement and whether or not our approach has been reliable.
That was an example of a home-grown classification system for a very specific project, but this idea of positionality is embedded even in the very old, institutionalized classification systems that are used around the world. So, the International Classification of Diseases is a tool that’s used internationally to identify and classify health problems. And it actually underpins a lot of the US healthcare billing system.

This is an example of the different codes you can use in the ICD for being harmed by birds. So there is a code for having been harmed by a chicken, or a goose, or a parrot. There is no code for ostrich, though. Okay. Think about how big an ostrich is. And then think about maybe living in Australia. If you ask an Australian what is going to be a more risky, harmful health situation, being kicked by an ostrich or being bitten by a goose? Probably they’re gonna think the ostrich is the more important thing to count.
But the ICD, it wasn’t developed with that in mind. The ICD was developed with its origins in the 1850s. It’s now maintained by the WHO. And it was designed primarily by white men in Western Europe and North America. Their positionality, it’s embedded in the ICD today and it will continue to be unless we routinely question what that positionality looks like.
Ultimately, choices here are inevitable. And this idea of removing bias, it just doesn’t jive when we’re understanding that these choices are gonna happen regardless. A lot of the conversation about debiasing algorithms is about adding rows. If you just add enough data, you’ll be able to get a representative view of the world. But if you limit yourself to only the columns for parrot, chicken, and goose and you don’t have a column for ostrich, you will never capture how many ostrich kicks there were.
So, if the debiasing debate isn’t helpful what do we do instead? We argue that you could look towards being positionality-aware. And we suggest that there are three basic steps that machine learning engineers and others involved in the process can take.
The first is to uncover positionality in your own workflows. Look not only at the classification systems but also the data and the models that you’re making use of, and think about where positionality enters. Keep track of it.
Next is to trying to assure there’s context alignment. That’s an alignment between the classification system and the context in which it was developed, and the actual application scenario for the machine learning tool that you are creating.
And here let’s return to that online harassment example. We developed that for Twitter. Maybe we want to use it on Reddit now. If you’re thinking about just taking the model that was created for Twitter and applying it to Reddit, there’s very few options for embedding a positionality-aware approach. If you’re thinking about well maybe if I just feed in a bunch of new data I can solve the problem—so you trained it on Twitter data, now you’re going to train it on Reddit data, that’ll get you closer. But what you actually need to do is question that classification system. You need to go back and look at how you’re actually assessing what counts as harassment and what doesn’t.
Because the way people communicate on Twitter is different from Reddit. On Twitter you have a short character count. You might use hashtags, at-replies. On Reddit you are probably talking in very specific subreddits. You’re probably engaging in particular language because you know there’s a moderator watching what you’re doing and keeping track to make sure that you’re within the bounds of what that community has deemed to be acceptable. You have way more space to do it, right. And so the ways that we classify content for Twitter and Reddit, they’re probably going to be different. Certainly the ways we train our annotators has to be different, because those approaches do not work when the content and the context are completely changed.
The last step here is to remember that you need to be continually trying to ensure that that alignment exists. The models might change, the data might change, the classification systems themselves might change. The ICD, it’s changed by the WHO relatively routinely. And so if you’re making use of it, you need to update your approaches.
It’s also important to recognize that the context in which you’re building something might change whether you like it or not. And so having a lack of control there kind of requires you to be aware of what’s shifting, in order to build a reasonable and responsible tool.
So, with all of this in mind, what we did was run a workshop with ML engineers, and we’ve got a number of other workshops already submitted. So we’ve submitted to EPIC and FAT*. We’ve created a white paper that’s available on our web site and plan to write a more detailed position paper that we can make available widely.
I will let you go explore the web site on your own, but before I do that I just want to leave you with this: Right now, ML and AI systems kind of are like a one-size-fits-all t‑shirt. They fit very few people, a lot of us end up kind of unhappy. But we can do better. We can harness this opportunity to be aware of the very specific contexts in which these tools can be deployed, think about how they can be tracked over time, and find ways to serve the specific needs of the users and the developers in order to be aware of the particular perspective from which we are designing and that perspective which is embedded in all of the tools we’re creating. Thanks.