
Tobi Hahn: Hi, I’m Tobi. I’m @rainshapes on Twitter.
I made a bot called @corruptum, and he uses a lot of copyrighted content in his corpus, so I was wondering whether it was legal and whether its use qualified as Fair Use.
https://mobile.twitter.com/corruptum/status/413444762965118976
This is the bot. This is probably its best tweet ever. It takes some characters from one source and some characters from another source and puts them together to kind of put them together in a weird way.
Moving on to Fair Use, most of the copyrighted content that it contains isn’t identifiable in the context of the tweets, except for 10 PRINT, which it uses a lot of the bibliography of, for some reason. I don’t really remember why I put that there. Just for a while when I was working on this bot, when I found something on the Internet I would just paste it in and that was how it went.
https://mobile.twitter.com/corruptum/status/526576561827627008
This is from a Roman guide book. It says “from silk, China received nuts, sesame seeds and grapes from Persia, spices Mantua, ran the smaller city-states” That’s from a history book that I put into it, and when you search that in Google, it comes up with nothing. So it’s really difficult to discern that this is a piece of copyrighted content.
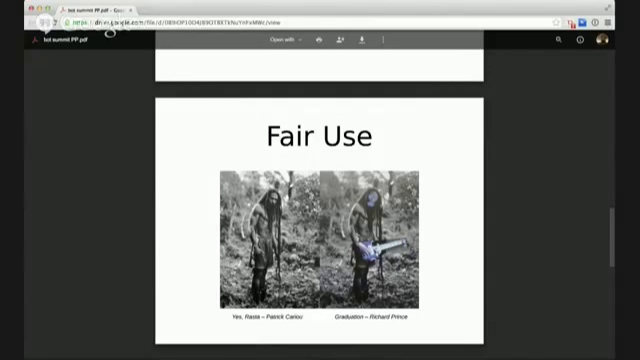
But in terms of Fair Use, I think it would qualify as Fair Use. It’s kind of juxtaposing two different sources together to create a pastiche, and there’s some legal precedence for it. On the left, this is “Yes Rasta” by Patrick Cariou, and this is “Graduation” by Richard Prince, and Cariou sued Prince for his use of his artwork in “Graduation” but [Prince] won in an appeal because the court found that this use was transformative. So I think if the uses of the source are juxtaposed in a way that lets you create a new reading and way to look at the sources, then it could be Fair Use.
If for some reason someone managed to figure out that it was using copyrighted material and decided that they did not want it used in the bot, they would have to file a DMCA request to Twitter. Twitter’s received about 10,000 of them in six months, and about 76% of the material affected by the takedown requests were removed. Only 18 counter-notices were sent and 100% of them were successful. So I think that if someone were to contest the bot’s use of it, I don’t think the DMCA takedown would be successful. And according to the DMCA, the person sending the takedown request has to consider the possibility of Fair Use before sending the request.
And that’s all I have. Thank you. But I some discussion questions. How much do you think a bot would have to alter its corpus for it to be transformative? If it just had one source and it fed it through a Markov chain, could that potentially count as a transformative use?
Darius Kazemi: Thank you for the prompt there. We have some time for discussion for this. Nick
Nick Montfort: A number of legal factors [inaudible] short phrases are not afforded copyright protection and what exactly a short phrase means is a question that requires some legal research and that is probably not entirely clear. But that would also be an issue for taking little bits of text and using them in a bot.
Erin McKean: It has some bearing, how long the source text is. So that’s why a line from a song lyric is often more contentious than a line from War and Peace.
Nick: And also how aggressive the intellectual property owners are.
Erin: Yeah.
[Inaudible EM/NM cross-talk]
[The “Audience #” comments below are from people off-screen. Tried to keep them all distinct, but there may be errors in attribution.]
Audience 1: I’m an awful person. I don’t remember who actually made the Top Gun-tweeting robot.
Darius: That’s Ramsey Nasser.
Audience 1: Because I remember that got DMCA’d. I just don’t know if Ramsay never sent an [appellation?] or if that was—
Darius: I don’t think he filed a counter-claim, but we could ask. He’s not in the chat.
Audience 1: It’s the only thing I’m aware of that I’ve actually seen that happen to in the bot community.
Darius: For those who don’t know, Ramsay’s Top Gun bot was called 555 µHz and it basically sampled the movie Top Gun once every twenty-four frames and showed each frame of the movie, with subtitles. So over time, in theory, it’s like watching Top Gun over the course of six months or something. His idea was that it was transformative, and whoever owns it, Warner or I forgot who owns it, was like, “No. This is not transformative, you’re just showing the movie very slowly.” Paramount, it’s Paramount. Thank you Zach in chat.
Audience 1: I have a related question. I wonder if you know the nature of those DMCA requests. Like how many of them were for example URLs to pirated content, or something like that.
Tobi: I think there was a lot of them and I remember there were statistics in Twitter’s transparency report that showed how many were images and how many were links but I don’t remember them all off the top of my head.
Audience 2: But is the copyrighted content in the tweet?
Audience 1: I’m curious how many of those were pure text, for example.
Darius: Right, where the tweet itself was the copyrighted content versus just linking to pirated stuff. That’s an interesting question as well. It’d be interesting to see a study, if possible, of all the DMCA stuff, if it’s even available. People are mentioning Chilling Effects in the IRC chat. That’s a website that tracks these takedown notices, so maybe that could be mined for more information about this.
Brett O’Connor: This isn’t really a legal-related thing, but I do recall once seeing a tweet to Olivia Taters, Rob’s bot, that was someone saying, “Why did you just take my words and then mix them up.” I’m wondering if anybody has had anybody contact them—
Darius: That happens all the time with my bots. I have one called Professor Jocular that finds tweets that are Favstar fave of the day, so they’re usually jokes, and then attempts to make a really poor description of why it’s funny. I don’t @-reply people because that would get flagged for spam, but I do .@-reply their names so that there’s at least some kind of attribution going on there. So I try to attribute, but still people respond and they’re just like, “Tweet stealer! Joke stealer.” Because there’s this whole—especially in comedy Twitter—there’s this whole who stole whose joke, who was the first one to tell this Twitter joke, all that sort of thing. And sometimes it’s not stealing, it’s just a really awful, banal joke that anyone has come up with multiple times. Other times there are really great, funny people on Twitter whose jokes then just get stolen by those TED parody accounts, so yeah. I get it all the time.
I’ve seen it happen more than once to Olivia, and basically anything that sources text that is then re-presented in an identifiable form, it’s possible someone will find that and use it. I like Allison’s Pizza Clones. [It] does an interesting thing with attribution where you embed the tweets that you’re taking the text from, right?
Allison Parrish: Yeah. I don’t know if that’s the best way to do it but [inaudible]
Darius: It’s interesting. And Olivia faves as attribution. That’s why Olivia faves your tweets sometimes. It means your tweet has been added to her [pulsing?] database.
Audience 3: But that’s probably what alerts the user.
Darius: Right, it does.
Audience 3: So that’s kind of cool.
Audience 4: By follow-up, 555 µHz, Ramsay did not do a counter-claim. Because he wasn’t sure about his options and the process seemed to be extremely confusing.
Further Reference
Darius Kazemi’s home page for Bot Summit 2014, with YouTube links to individual sessions, and a log of the IRC channel.