
Jonathon Penney: I Jon Penney. I’m a legal academic and social scientist. I teach law in Canada at Dalhousie University. I’m also a research fellow at University of Toronto’s Citizen Lab and a research affiliate at Princeton’s Center for Information Technology Policy.
Merry Mou: Hi, I’m Merry, and I worked with Nathan over the last year on CivilServant while a master’s student at MIT and now I’m a network security engineer at a network security startup.
Penney: So before I begin I just wanted to first say thanks to Nathan for giving us the chance to come here and talk about our research and being part of this incredible community that he brought together. So thank you, Nathan.

So this is the title of our project and you know, it sounds a bit complicated. It sounds a bit academic. But actually underlying this project is a pretty simple and we think powerful idea that provides a solution to a complex challenge that’s facing online communities like Twitter, like Reddit, within the CivilServant universe. That challenge is the increasing automation of the enforcement of legal rules and norms online.

Our solution… No, it’s not sending robots to law school. To borrow Ethan’s line, we’re not that evil and inhumane. But it does involve building our own automated processes, even bots, that can provide a means of protecting and reducing some of the negative effects associated with this automation of legal norms.
So that’s sort of the idea behind the project and we intend to carry it out through the model of citizen science associated with CivilServant. That is we hope our results and findings, which will be gained with having our bots essentially study copyright bots, and through those insights will power empower online communities to build their own solutions and deal with some of these negative effects.
So that’s the general idea. Let me say a little bit more about some of the specifics of this particular study.
So, a lot of people talk about artificial intelligence and the social revolution it’s going to foster. But when you think about legal rules and norms that revolution is already happening. Everywhere we look around us, laws and legal norms are increasingly being enforced and implied through technical, technological, and automated processes. From very rudimentary police spots, to red light cameras and speeding cameras, to DRM. And in the case of our study, copyright. Which is the focus of what we’re looking at in this study.
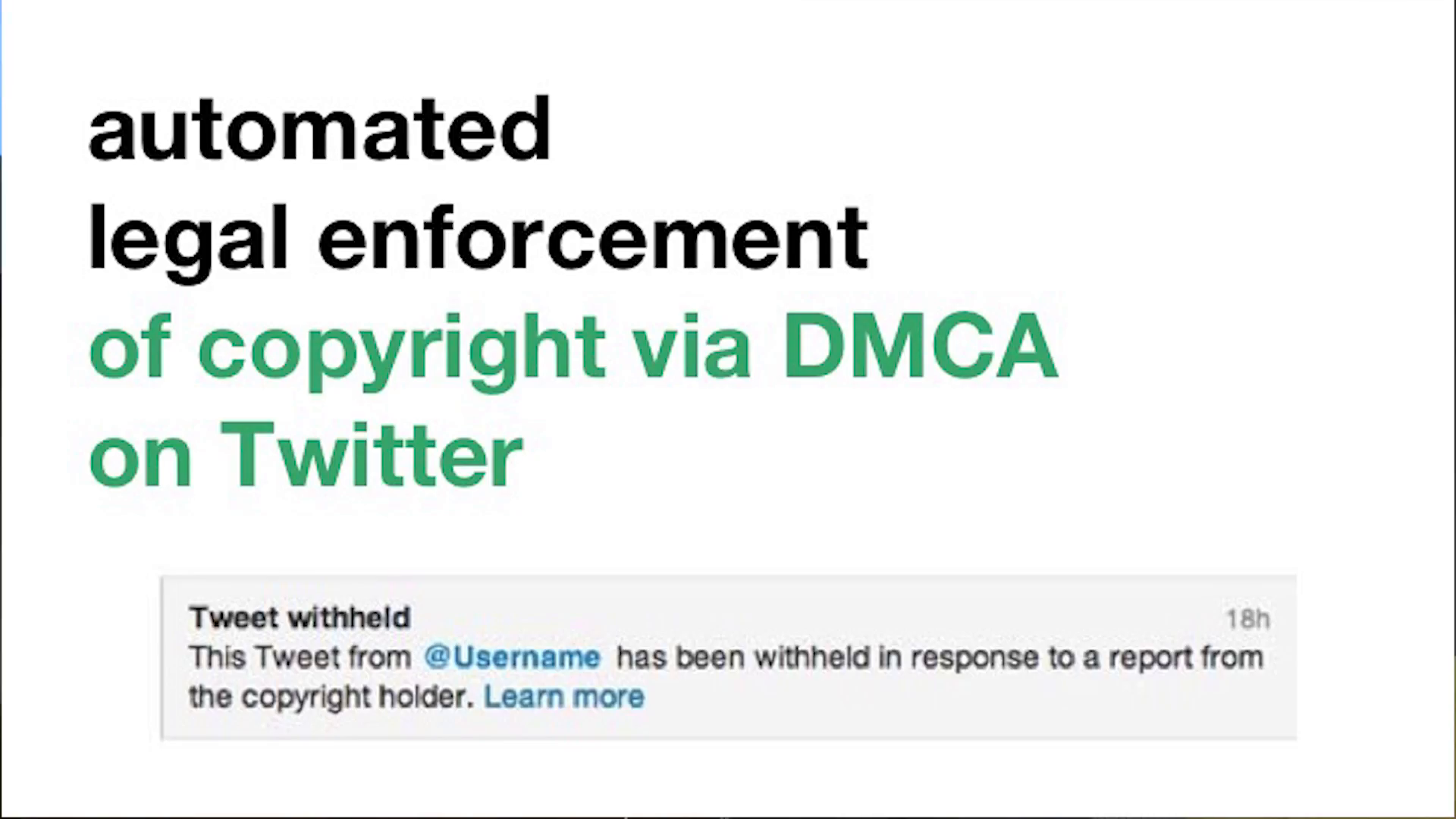
Now, as many of you are aware, the Digital Millennium Copyright Act—or at least I hope you’ve heard of it—also known as the DMCA, it’s essentially the statute or the regulatory regime by which copyright law in the United States is enforced online. It is done so primarily through DMCA copyright takedown notices being sent to users, which are effectively personally-received legal threats concerning content that users post online. And it’s a demand to have that content removed.
What’s happened today, and this was certainly not contemplated by the people who drafted the DMCA in 1998, is that now that enforcement has become increasingly automated. Essentially you have private entities that own and operate bots and automated programs that send out millions, and I mean literally millions, of these DMCA notices to Internet users all around the world on a daily basis.
So why is this a challenge? Well, because prior research including research that I have done and other social scientists have done, have shown that this kind of legal threat that’s received, or knowledge that someone is watching or monitoring you to deliver this kind of a notice, has a significant chilling effect on what people say and do online. That is, promotes a kind of self-censorship.
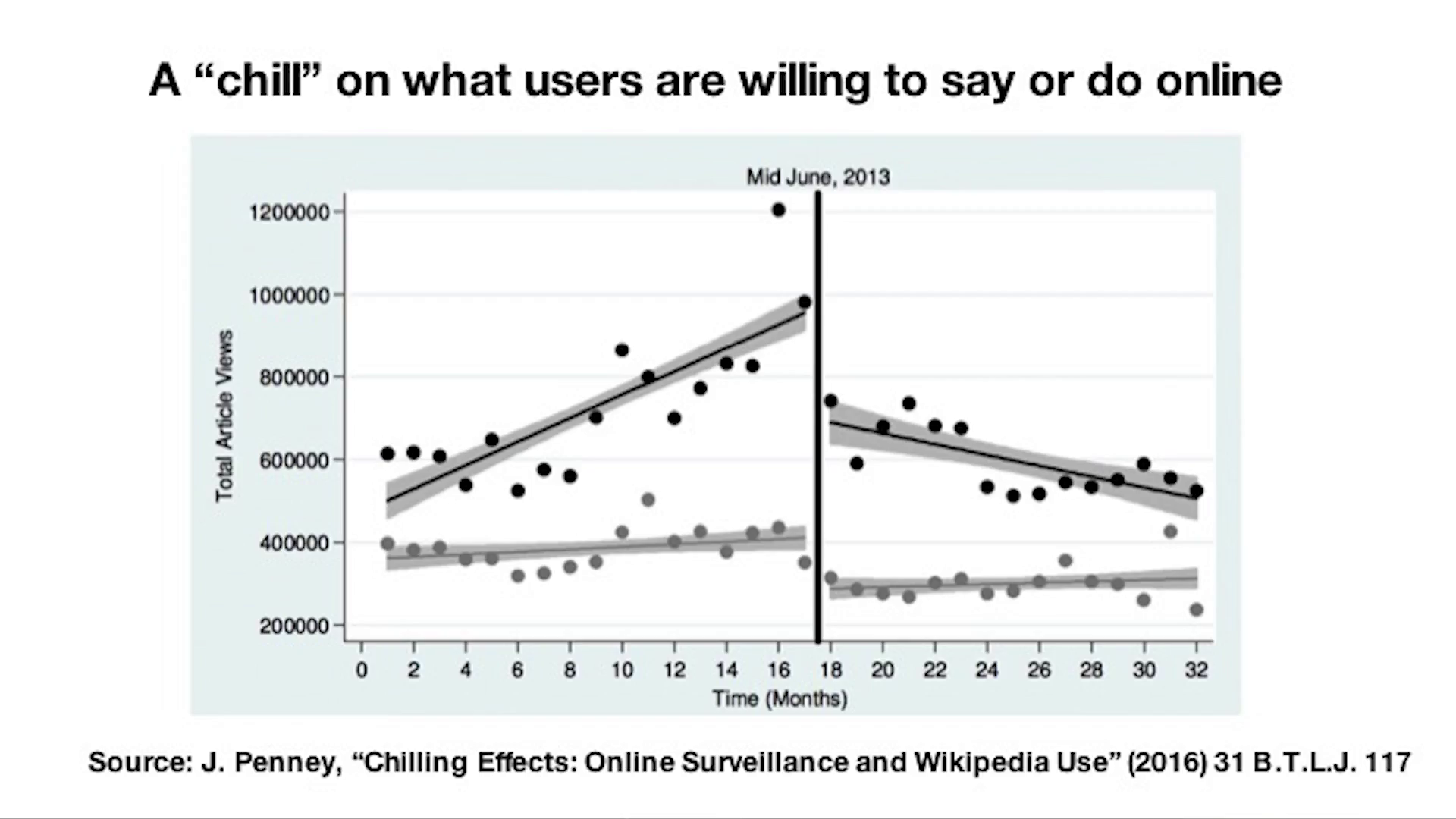
Graph source: Chilling Effects: Online Surveillance and Wikipedia Use
This is actually a graph from a paper that I published in 2016 where I used Wikipedia data to show that awareness of online surveillance actually has a chilling effect on what people are willing to read on Wikipedia online.
So, that’s a sense of some of the challenges associated with this research. The actual work, what we’re dealing with in this study, this notion of self-censorship is actually based on foundational behavioral theories associated with concerns about surveillance, concerns about social norms. But the point here is that these notices, millions of these threats being sent out on a day-to-day basis, we predict is having and promoting a significant climate of self-censorship in online communities.
Mou: So with that background of quantitative research and behavioral theories, we wanted to use CivilServant to answer two questions. The first is, does receiving a DMCA copyright takedown notice on Twitter cause that user to tweet less often in the future? And we’re hoping that this will provide additional quantitative evidence for the aforementioned negative chilling effects that might occur.
The second question we want to answer with CivilServant is, can we design interventions, basically on Twitter—Twitter bots—that are based on the behavioral theories that might change how people react to these takedown requests?
So right now, if you’re a user on Twitter and you make a tweet, there’s a lot of companies and bots who are interested in taking down potential violations. They’ll send a notice to Twitter and Twitter will often just take down these tweets without contest, due to the safe harbor provisions in DMCA. And at this point the user makes a decision both consciously and subconsciously about how to react to this notice.
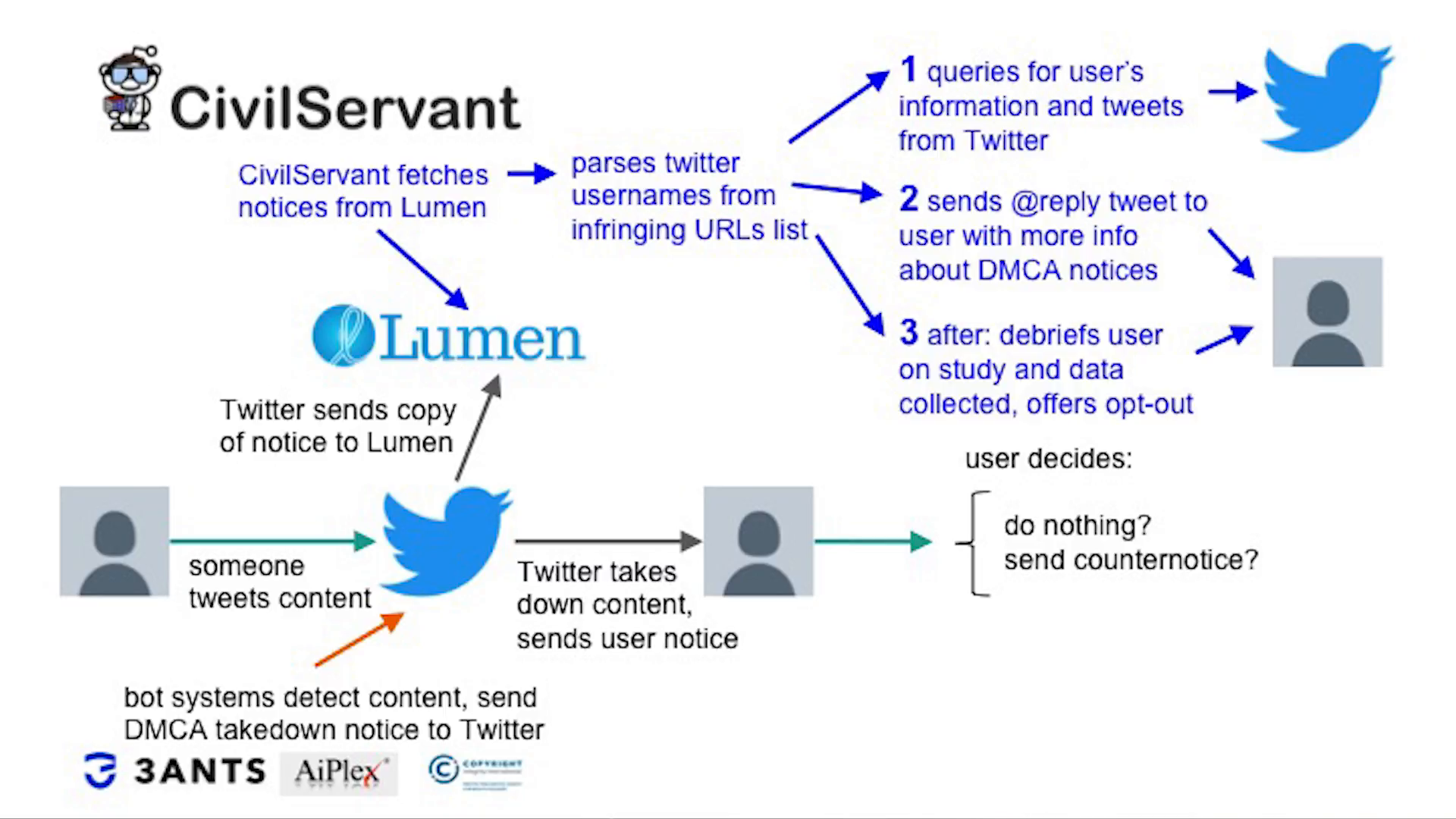
With CivilServant, we wanted to extend the software to detect when a user receives a notice by using Lumen, which is a public database of takedown notices across the Web, and you CivilServant to send a tweet back to that user with information about DMCA takedown notices. This content is designed based off of behavioral theories in the hopes that it will change how that user will respond to that takedown request.
So this study is still in progress and we’re excited to share the results of the study with you in the future. And we’re excited to be working with Nathan and with CivilServant on this idea that in an ecosystem of increasing automated legal enforcement and pervasive Web infrastructure, we as citizens can still build our own bots that could protect each other from these potential threats to our legal rights. Thank you.
Further Reference
Gathering the Custodians of the Internet: Lessons from the First CivilServant Summit at CivilServant